Blog
FAT filesystem integration into MOP2
19 November 2025
Hello, World!
I would like to present to you FAT filesystem integration into the MOP2 operating system! This was
possible thanks to fat_io_lib library by UltraEmbedded, because there’s no way I’m writing an
entire FAT driver from scratch ;).
Source for fat_io_lib: https://github.com/ultraembedded/fat_io_lib
Needed changes and a "contextual" system
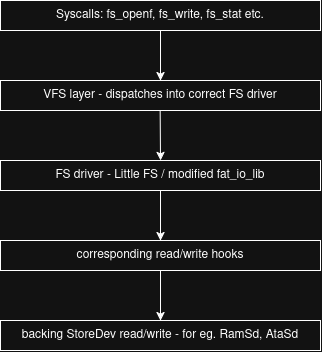
Integrating fat_io_lib wasn’t so straightforward as I thought it would be. To understand the problem we need to first understand the current design of MOP2’s VFS.
MOP2’s VFS explained
The VFS (ie. Virtual File System) is a Windows/DOS-style labeled VFS. Mountpoints are identified by
a label, like for eg. sys:/boot/mop2 or base:/scripts/mount.tb, which kinda looks like
C:\Path\To\File in Windows. I’ve chosen this style of VFS over the UNIX kind, because it makes more
sense to me personally. A mountpoint label can point to a physical device, a virtual device (ramsd)
or a subdevice/partition device. In the UNIX world on the other hand, we have a hierarchical VFS, so
paths look like /, /proc, /dev, etc. This is a little confusing to reason about, because you’d
think that if / is mounted let’s say on a drive sda0, then /home would be a home directory
within the root of that device. This is not always the case. / can be placed on sda0, but /home
can be placed on sdb0, so now something that looks like a subdirectory, is now a pointer to an
entirely different media. Kinda confusing, eh?
The problem
So now that we know how MOP2’s VFS works, let’s get into low-level implementation details. To handle mountpoints we use a basic hashtable. We just map the label to the proper underlying file system driver like so:
base -> Little FS
uhome -> Little FS
sys -> FAT16Through this table, we can see that we have two mountpoints (base and uhome), which both use Little FS, but are placed on different media entirely. Base is located on a ramsd, which is entirely virtual and uhome is a partition on a physical drive.
To manage such setup, we need to have separate filesystem library contexts for each mountpoint.
A context here means an object, which stores info like block size, media read/write/sync hooks,
media capacity and so on. Luckly, with Little FS we could do this out of the box, because it blesses
us with lfs_t - an instance object. We can then create this object for each Little FS mountpoint.
Internals of the VFS mountpoint structure
typedef struct VfsMountPoint {
int _hshtbstate;
char label[VFS_MOUNTPOINT_LABEL_MAX];
int32_t fstype;
StoreDev *backingsd;
VfsObj *(*open)(struct VfsMountPoint *vmp, const char *path, uint32_t flags);
int32_t (*cleanup)(struct VfsMountPoint *vmp);
int32_t (*stat)(struct VfsMountPoint *vmp, const char *path, FsStat *statbuf);
int32_t (*fetchdirent)(struct VfsMountPoint *vmp, const char *path, FsDirent *direntbuf, size_t idx);
int32_t (*mkdir)(struct VfsMountPoint *vmp, const char *path);
int32_t (*delete)(struct VfsMountPoint *vmp, const char *path);
// HERE: instance objects for the underlying filesystem driver library.
union {
LittleFs littlefs;
FatFs fatfs;
} fs;
SpinLock spinlock;
} VfsMountPoint;
typedef struct {
SpinLock spinlock;
VfsMountPoint mountpoints[VFS_MOUNTPOINTS_MAX];
} VfsTable;
// ...Little FS init code
int32_t vfs_init_littlefs(VfsMountPoint *mp, bool format) {
// Configure Little FS
struct lfs_config *cfg = dlmalloc(sizeof(*cfg));
memset(cfg, 0, sizeof(*cfg));
cfg->context = mp;
cfg->read = &portlfs_read; // Our read/write hooks
cfg->prog = &portlfs_prog;
cfg->erase = &portlfs_erase;
cfg->sync = &portlfs_sync;
cfg->block_size = LITTLEFS_BLOCK_SIZE;
cfg->block_count = mp->backingsd->capacity(mp->backingsd) / LITTLEFS_BLOCK_SIZE;
// left out...
int err = lfs_mount(&mp->fs.littlefs.instance, cfg);
if (err < 0) {
ERR("vfs", "Little FS mount failed %d\n", err);
return E_MOUNTERR;
}
// VFS hooks
mp->cleanup = &littlefs_cleanup;
mp->open = &littlefs_open;
mp->stat = &littlefs_stat;
mp->fetchdirent = &littlefs_fetchdirent;
mp->mkdir = &littlefs_mkdir;
mp->delete = &littlefs_delete;
return E_OK;
}So where is the problem? It’s in the fat_io_lib library. You see, the creators of Little FS thought this out pretty well and designed their library in such manner that we can do cool stuff like this. The creators of fat_io_lib on the other hand… yeah. Here are the bits of internals of fat_io_lib:
//-----------------------------------------------------------------------------
// Locals
//-----------------------------------------------------------------------------
static FL_FILE _files[FATFS_MAX_OPEN_FILES];
static int _filelib_init = 0;
static int _filelib_valid = 0;
static struct fatfs _fs;
static struct fat_list _open_file_list;
static struct fat_list _free_file_list;There’s no concept of a "context" - everything is thrown into a bunch of global variables. To clarify: THIS IS NOT BAD! This is good if you need a FAT library for let’s say a microcontroller, or some other embedded device. Less code/stuff == less memory usage and so on.
When I was searching online for a FAT library, I wanted something like Little FS, but to my suprise there are no libraries for FAT designed like this? Unless it’s a homebrew OsDev project, of course. I’ve even went on reddit to ask and got nothing, but cricket noises ;(.
I’ve decided to modify fat_io_lib to suit my needs. I mean, most of the code is already written for me anyway, so I’m good.
The refactoring was quite easy to my suprise! The state of the library is global, but it’s all nicely placed in one spot, so we can then move it out into a struct:
struct fat_ctx {
FL_FILE _files[FATFS_MAX_OPEN_FILES];
int _filelib_init;
int _filelib_valid;
struct fatfs _fs;
struct fat_list _open_file_list;
struct fat_list _free_file_list;
void *extra; // we need this to store a ref to the mountpoint to access storage device hooks
};// This is what our VfsMountPoint struct from earlier was referencing, BTW.
typedef struct {
struct fat_ctx instance;
} FatFs;I’ve then gone on a compiler error hunt for about 2 hours! All I had to do is change references for
eg. from _fs.some_field into ctx→_fs.some_field. It was all pretty much brainless work - just
compile the code, read the error line number, edit the variable reference, repeat.
Why do I even need FAT in MOP2?
I need it, because Limine (the bootloader) uses FAT16/32 (depending on what the user picks) to store the kernel image, resource files and the bootloader binary itself. It’d be nice to be able to view all of these files and manage them, to maybe in the future for eg. update the kernel image from the system itself (self-hosting, hello?).
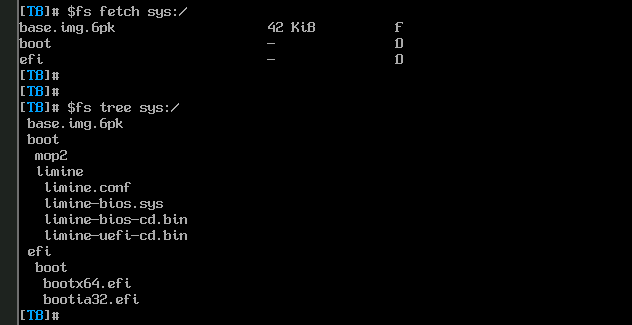
Fruits of labour
Here are some screenshots ;).
MBus - in-kernel messaging system
12 November 2025
In this article I would like to present to you MBus - a kernel-space messaging IPC mechanism for
the MOP2 operating system.
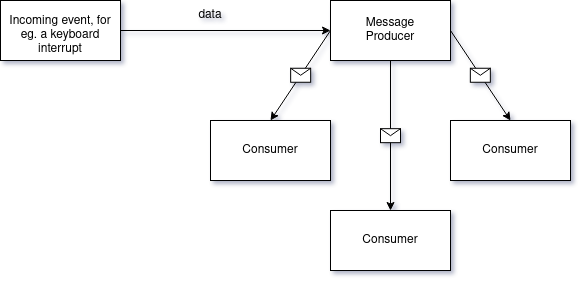
One-to-many messaging
MBus is a one-to-many messaging system. This means that there’s one sender/publisher and many readers/subscribers. Think of a YouTube channel - a person posts a video and their subscribers get a push notification that there’s content to consume.
User-space API
This is the user-space API for MBus. The application can create a message bus for objmax
messages of objsize. Message buses are indentified via a global string ID, for eg. the PS/2
keyboard driver uses ID "ps2kb".
ipc_mbusattch and ipc_mbusdttch are used for attaching/detattching a consumer to/from the
message bus.
int32_t ipc_mbusmake(char *name, size_t objsize, size_t objmax);
int32_t ipc_mbusdelete(char *name);
int32_t ipc_mbuspublish(char *name, const uint8_t *const buffer);
int32_t ipc_mbusconsume(char *name, uint8_t *const buffer);
int32_t ipc_mbusattch(char *name);
int32_t ipc_mbusdttch(char *name);Usage
The usage of MBus can be found for eg. inside of TB - the MOP2’s shell:
Initalizing interactive shell mode
if (CONFIG.mode == MODE_INTERACTIVE) {
ipc_mbusattch("ps2kb");
do_mode_interactive();
// ...Reading key presses
// ...
int32_t read = ipc_mbusconsume("ps2kb", &b);
if (read > 0) {
switch (b) {
case C('C'):
case 0xE9:
uprintf("\n");
goto begin;
break;
case C('L'):
uprintf(ANSIQ_CUR_SET(0, 0));
uprintf(ANSIQ_SCR_CLR_ALL);
goto begin;
break;
}
// ...Previously reading the keyboard was done in a quite ugly manner via specialized functions of the
ps2kbdev device object (DEV_PS2KBDEV_ATTCHCONS and DEV_PS2KBDEV_READCH). It was a one big
hack, but the MBus API has turned out quite nicely ;).
With the new MBus API, the PS/2 keyboard driver becomes way cleaner than before (you can dig through the commit history…).
Kernel-side code for the PS/2 keyboard driver
// ...
IpcMBus *PS2KB_MBUS;
void ps2kbdev_intr(void) {
int32_t c = ps2kb_intr();
if (c >= 0) {
uint8_t b = c;
ipc_mbuspublish("ps2kb", &b);
}
}
void ps2kbdev_init(void) {
intr_attchhandler(&ps2kbdev_intr, INTR_IRQBASE+1);
Dev *ps2kbdev;
HSHTB_ALLOC(DEVTABLE.devs, ident, "ps2kbdev", ps2kbdev);
spinlock_init(&ps2kbdev->spinlock);
PS2KB_MBUS = ipc_mbusmake("ps2kb", 1, 0x100);
}The messaging logic is ~20 lines of code now.
The tricky part
The trickiest part to figure out while implementing MBus was to implement
cleaning up dangling/dead consumers. In the current model, a message bus
doesn’t really know if a consumer has died without explicitly detattching
itself from the bus. This is solved by going through each message bus and
it’s corresponding consumers and deleting the ones that aren’t in the list
of currently running processes. This operation is ran every cycle of the
scheduler - you could say it’s a form of garbage collection. All of this
is implemented inside ipc_mbustick:
void ipc_mbustick(void) {
spinlock_acquire(&IPC_MBUSES.spinlock);
// Go through all message buses
for (size_t i = 0; i < LEN(IPC_MBUSES.mbuses); i++) {
IpcMBus *mbus = &IPC_MBUSES.mbuses[i];
// Skip unused slots
if (mbus->_hshtbstate != HSHTB_TAKEN) {
continue;
}
IpcMBusCons *cons, *constmp;
spinlock_acquire(&mbus->spinlock);
// Go through every consumer of this message bus
LL_FOREACH_SAFE(mbus->consumers, cons, constmp) {
spinlock_acquire(&PROCS.spinlock);
Proc *proc = NULL;
LL_FINDPROP(PROCS.procs, proc, pid, cons->pid);
spinlock_release(&PROCS.spinlock);
// If not on the list of processes, purge!
if (proc == NULL) {
LL_REMOVE(mbus->consumers, cons);
dlfree(cons->rbuf.buffer);
dlfree(cons);
}
}
spinlock_release(&mbus->spinlock);
}
spinlock_release(&IPC_MBUSES.spinlock);
}As you can see it’s a quite heavy operation and thus not ideal - but still way ahead of what we had before. I guess the next step would be to figure out a way to optimize this further, although the system doesn’t seem to take a noticable hit in performance (maybe do some benchmarks in the future?).
TB shell scripting for MOP2
08 November 2025
This post is about TB (ToolBox) - the shell interpreter for MOP2 operating system.
Invoking applications
Applications are invoked by providing an absolute path to the binary executable and the list of
arguments. In MOP2 paths must be formatted as MOUNTPOINT:/path/to/my/file. All paths are absolute
and MOP2 doesn’t support relative paths (there’s no concept of a CWD or current working directory).
Example of listing currently running processes
base:/bin/pctl lsTyping out the entire path might get tiresome. Imagine typing MOUNTPOINT:/path/to/app arg more args
every time you want to call an app. This is what TB aliases/macros are for. They make the user type
less ;).
Example of calling an application via an alias
$pctl lsNow that’s way better!
Creating new aliases
To create an alias we can type
mkalias pctl base:/bin/pctlAnd then we can use our $pctl!
But there’s another issue - we have to write aliases for every application, which isn’t better than
us typing out the entire path. Luckliy, there’s a solution for this. TB has two useful functions
that can help us solve this - eachfile and mkaliasbn.
eachfile takes a directory, an ignore list and a command, which is run for every entry in the said
directory. We can also access the current directory entry via special symbol called &EF-ELEM.
In base/scripts/rc.tb we can see the full example in action.
eachfile !.gitkeep base:/bin \
mkaliasbn &EF-ELEMThis script means: for each file in base:/bin (excluding .gitkeep), call mkaliasbn for the current
entry. mkaliasbn then takes the base name of a path, which is expanded by &EF-ELEM and creates
an alias. mkaliasbn just simply does mkalias <app> MP:/path/<app>.
Logging
In the UNIX shell there’s one very useful statement - set -x. set -x tells the shell to print out
executed commands. It’s useful for script debugging or in general to know what the script does (or
if it’s doing anything / not stuck). This is one thing that I hate about Windows - it shows up a
stupid dotted spinner and doesn’t tell you what it’s doing and you start wondering. Is it stuck?
Is it waiting for a drive/network/other I/O? Is it bugged? Can I turn of my PC? Will it break if I
do? The user SHOULD NOT have these kinds of questions. That’s why I believe that set -x is very
important.
I wanted to have something similar in TB, so I’ve added a setlogcmds function. It takes yes or
no as an argument to enable/disable logging. It can be invoked like so:
setlogcmds yesNow the user will see printed statements, for eg. during the system start up:
this is an init script!
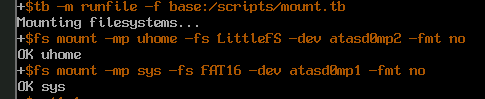
+$tb -m runfile -f base:/scripts/mount.tb
Mounting filesystems...
+$fs mount -mp uhome -fs LittleFS -dev atasd-ch0-M-part2 -fmt no
OK uhomeString stack and subshells
In UNIX shell, it’s common to get the output of an application, store it into a variable and then pass that variable around to other apps. For eg:
# Use of a subshell
MYVAR=$(cat file.txt)
echo $MYVAR | myapp # or something...In TB, I’ve decided to go with a stack, since I find it easier to implement than a variable hashmap. A stack can be implemented using any dynamic list BTW.
The stack in TB is manipulated via stackpush and stackpop functions. We can stackpush a string
using stackpush <my string> and then stackpop it to remove it. We can also access the top of
the stack via $stack. It’s a special magic alias, which expands to the string that is at the top.
An example of stack usage would be:
stackpush 'hello world string!'
print $stack
stackpopThe do function
The do function does what a subshell does in UNIX shell. We can do a command an then have it’s
output placed at the top of the stack. An example of this would be:
do print 'hello world from subshell'
print $stack
stackpopIt’s a simpler, more primitive mechanism than the UNIX subshells, but it gets the job done ;).
Intro to MOP2 programming
14 October 2025
This is an introductory post into MOP2 (my-os-project2) user application programming.
All source code (kernel, userspace and other files) are available at https://git.kamkow1lair.pl/kamkow1/my-os-project2.
Let’s start by doing the most basic thing ever: quitting an application.
AMD64 assembly
Hello program in AMD64 assembly
.section .text
.global _start
_start: // our application's entry point
movq $17, %rax // select proc_kill() syscall
movq $-1, %rdi // -1 means "self", so we don't need to call proc_getpid()
int $0x80 // perform the syscall
// We are dead!!As you can see, even though we’re on AMD64, we use int $0x80 to perform a syscall.
The technically correct and better way would be to implement support for syscall/sysret, but int $0x80 is
just easier to get going and requires way less setup. Maybe in the future the ABI will move towards
syscall/sysret.
int $0x80 is not ideal, because it’s a software interrupt and these come with a lot of interrupt overhead.
Intel had tried to solve this before with sysenter/sysexit, but they’ve fallen out of fasion due to complexity.
For purposes of a silly hobby OS project, int $0x80 is completely fine. We don’t need to have world’s best
performance (yet ;) ).
"Hello world" and the debugprint() syscall
Now that we have our first application, which can quit at a blazingly fast speed, let’s try to print something. For now, we’re not going to discuss IPC and pipes, because that’s a little complex.
The debugprint() syscall came about as the first syscall ever (it even has an ID of 1) and it was used for
printing way before pipes were added into the kernel. It’s still useful for debugging purposes, when we want to
literally just print a string and not go through the entire pipeline of printf-style formatting and only then
writing something to a pipe.
Usage of
debugprint() in AMD64 assembly.section .data
STRING:
.string "Hello world!!!"
.section .text
.global _start
_start:
movq $1, %rax // select debugprint()
lea STRING(%rip), %rdi // load STRING
int $0x80
// quit
movq $17, %rax
movq $-1, %rdi
int $0x80Why are we using lea to load stuff? Why not movq? Because we can’t…
We can’t just movq, because the kernel doesn’t support relocatable code - everything is loaded at a fixed
address in a process' address space. Because of this, we have to address everything relatively to %rip
(the instruction pointer). We’re essentially writing position independent code (PIC) by hand. This is what
the -fPIC GCC flag does, BTW.
Getting into C and some bits of ulib
Now that we’ve gone overm how to write some (very) basic programs in assembly, let’s try to untangle, how we get
into C code and understand some portions of ulib - the userspace programming library.
This code snippet should be understandable by now: ._start.S
.extern _premain
.global _start
_start:
call _premainHere _premain() is a C startup function that gets executed before running main(). _premain() is also
responsible for quitting the application.
_premain.c
// Headers skipped.
extern void main(void);
extern uint8_t _bss_start[];
extern uint8_t _bss_end[];
void clearbss(void) {
uint8_t *p = _bss_start;
while (p < _bss_end) {
*p++ = 0;
}
}
#define MAX_ARGS 25
static char *_args[MAX_ARGS];
size_t _argslen;
char **args(void) {
return (char **)_args;
}
size_t argslen(void) {
return _argslen;
}
// ulib initialization goes here
void _premain(void) {
clearbss();
for (size_t i = 0; i < ARRLEN(_args); i++) {
_args[i] = umalloc(PROC_ARG_MAX);
}
proc_argv(-1, &_argslen, _args, MAX_ARGS);
main();
proc_kill(proc_getpid());
}First, in order to load our C application without UB from the get go, we need to clear the BSS section of an
ELF file (which MOP2 uses as it’s executable format). We use _bss_start and _bss_end symbols for that, which
come from a linker script defined for user apps:
link.ld - linker script for user apps
ENTRY(_start)
SECTIONS {
. = 0x400000;
.text ALIGN(4K):
{
*(.text .text*)
}
.rodata (READONLY): ALIGN(4K)
{
*(.rodata .rodata*)
}
.data ALIGN(4K):
{
*(.data .data*)
}
.bss ALIGN(4K):
{
_bss_start = .;
*(.bss .bss*)
. = ALIGN(4K);
_bss_end = .;
}
}After that, we need to collect our application’s commandline arguments (like argc and argv in UNIX-derived
systems). To do that we use a proc_argv() syscall, which fills out a preallocated memory buffer with. The main
limitation of this approach is that the caller must ensure that enough space withing the buffer was allocated.
25 arguments is enough for pretty much all appliations on this system, but this is something that may be a little
problematic in the future.
After we’ve exited from main(), we just gracefully exit the application.
"Hello world" but from C this time
Now we can program our applications the "normal"/"human" way. We’ve gone over printing in assembly using the
debugprint() syscall, so let’s now try to use it from C. We’ll also try to do some more advanced printing
with (spoiler) uprintf().
Calling
debugprint() from C// Import `ulib`
#include <ulib.h>
void main(void) {
debugprint("hello world");
}That’s it! We’ve just printed "hello world" to the terminal! How awesome is that?
uprintf() and formatted printing#include <ulib.h>
void main(void) {
uprintf("Hello world %d %s %02X\n", 123, "this is a string literal", 0xBE);
}uprintf() is provided by Eyal Rozenberg (eyalroz), which originates from Macro Paland’s printf. This printf
library is super easily portable and doesn’t require much in terms of standard C functions and headers. My main
nitpick and a dealbreaker with other libraries was that they advertise themsevles as "freestanding" or "made for
embedded" or something along those lines, but in reality they need so much of the C standard library, that you
migh as well link with musl or glibc and use printf from there. And generally speaking, this is an issue with
quite a bit of "freestanding" libraries that you can find online ;(.
Printf rant over…
Error codes in MOP2 - a small anecdote
You might’ve noticed is that main() looks a little different from standard C main(). There’s
no return/error code, because MOP2 simply does not implement such feature. This is because MOP2 doesn’t follow the
UNIX philosophy.
The UNIX workflow consists of combining many small/tiny programs into a one big commandline, which transforms text into some more text. For eg.:
Example bash command (Linux) to get a name of /proc/meminfo field
cat /proc/meminfo | awk 'NR==20 {print $1}' | rev | cut -c 2- | revPersonally, I dislike this type of workflow. I prefer to have a few programs that perform tasks groupped by topic,
so for eg. in MOP2, we have $fs for working with the filesystem or $pctl for working with processes. When we
approach things the MOP2 way, it turns out error codes are kind of useless (or at least they wouldn’t get much
use), since we don’t need to connect many programs together to get something done.
Printing under the hood - intro to pipes
Let’s take a look into what calling uprintf() actually does to print the characters post formatting. The printf
library requires the user to define a putchar_() function, which is used to render a single character.
Personally, I think that this way of printing text is inefficient and it would be better to output and entire
buffer of memory, but oh well.
putchar.c
#include <stdint.h>
#include <system/system.h>
#include <printf/printf.h>
void putchar_(char c) {
ipc_pipewrite(-1, 0, (uint8_t *const)&c, 1);
}To output a single character we write it into a pipe. -1 means that the pipe belongs to the calling process, 0 is an ID into a table of process' pipes - and 0 means percisely the output pipe. In UNIX, the standard pipes are numbered as 0 = stdin, 1 = stdout and 2 = stderr. In MOP2 there’s no stderr, everything the application outputs goes into the out pipe (0), so we can just drop that entirely. We’re left with stdin/in pipe and stdout/out pipe, but I’ve decided to swap them around, because the out pipe is used more frequently and it made sense to get it working first and only then worry about getting input.
Pipes
MOP2 pipes are a lot like UNIX pipes - they’re a bidirectional stream of data, but there’s slight difference in the interface. Let’s take a look at what ulib defines:
Definitions for ipc_pipeXXX() calls
int32_t ipc_piperead(PID_t pid, uint64_t pipenum, uint8_t *const buffer, size_t len);
int32_t ipc_pipewrite(PID_t pid, uint64_t pipenum, const uint8_t *buffer, size_t len);
int32_t ipc_pipemake(uint64_t pipenum);
int32_t ipc_pipedelete(uint64_t pipenum);
int32_t ipc_pipeconnect(PID_t pid1, uint64_t pipenum1, PID_t pid2, uint64_t pipenum2);In UNIX you have 2 processes working with a single pipe, but in MOP2, a pipe is exposed to the outside world and anyone can read and write to it, which explains why these calls require a PID to be provided (indicates the owner of the pipe).
Example of ipc_piperead() - reading your applications own input stream
#include <stddef.h>
#include <stdint.h>
#include <ulib.h>
void main(void) {
PID_t pid = proc_getpid();
#define INPUT_LINE_MAX 1024
for (;;) {
char buffer[INPUT_LINE_MAX];
string_memset(buffer, 0, sizeof(buffer));
int32_t nrd = ipc_piperead(pid, 1, (uint8_t *const)buffer, sizeof(buffer) - 1);
if (nrd > 0) {
uprintf("Got something: %s\n", buffer);
}
}
}ipc_pipewrite() is a little boring, so let’s not go over it. Creating, deleting and connecting pipes is where
things get interesting.
A common issue, I’ve encountered, while programming in userspace for MOP2 is that I’d want to spawn some external
application and collect it’s output, for eg. into an ulib StringBuffer or some other akin structure. The
obvious thing to do would be to (since everything is polling-based) spawn an application, poll it’s state (not
PROC_DEAD) and while polling, read it’s out pipe (0) and save it into a stringbuffer. The code to do this would
look something like this:
Pipe lifetime problem illustration
#include <stddef.h>
#include <stdint.h>
#include <ulib.h>
void main(void) {
StringBuffer outsbuf;
stringbuffer_init(&outsbuf);
char *appargs = { "-saystring", "hello world" };
int32_t myapp = proc_spawn("base:/bin/myapp", appargs, ARRLEN(appargs));
proc_run(myapp);
// 4 == PROC_DEAD
while (proc_pollstate(myapp) != 4) {
int32_t r;
char buf[100];
string_memset(buf, 0, sizeof(buf));
r = ipc_piperead(myapp, 0, (uint8_t *const)buf, sizeof(buf) - 1);
if (r > 0) {
stringbuffer_appendcstr(&outsbuf, buf);
}
}
// print entire output
uprintf("%.*s\n", (int)outsbuf.count, outsbuf.data);
stringbuffer_free(&outsbuf);
}Can you spot the BIG BUG? What if the application dies before we manage to read data from the pipe, taking the pipe down with itself? We’re then stuck in this weird state of having incomplete data and the app being reported as dead by proc_pollstate.
This can be easily solved by changing the lifetime of the pipe we’re working with. The parent process shall allocate a pipe, connect it to it’s child process and make it so that a child is writing into a pipe managed by it’s parent.
Pipe lifetime problem - the solution
#include <stddef.h>
#include <stdint.h>
#include <ulib.h>
void main(void) {
PID_t pid = proc_getpid();
StringBuffer outsbuf;
stringbuffer_init(&outsbuf);
char *appargs = { "-saystring", "hello world" };
int32_t myapp = proc_spawn("base:/bin/myapp", appargs, ARRLEN(appargs));
// take a free pipe slot. 0 and 1 are already taken by default
ipc_pipemake(10);
// connect pipes
// myapp's out (0) pipe --> pid's 10th pipe
ipc_pipeconnect(myapp, 0, pid, 10);
proc_run(myapp);
// 4 == PROC_DEAD
while (proc_pollstate(myapp) != 4) {
int32_t r;
char buf[100];
string_memset(buf, 0, sizeof(buf));
r = ipc_piperead(myapp, 0, (uint8_t *const)buf, sizeof(buf) - 1);
if (r > 0) {
stringbuffer_appendcstr(&outsbuf, buf);
}
}
// print entire output
uprintf("%.*s\n", (int)outsbuf.count, outsbuf.data);
ipc_pipedelete(10);
stringbuffer_free(&outsbuf);
}Now, since the parent is managing the pipe and it outlives the child, everything is safe.
Hello World!
09 September 2025
This is a hello world post!
#include <stdio.h>
int main(void) {
printf("Hello World!\n");
return 0;
}Enjoy the blog! More posts are coming in the near future!
Older posts are available in the archive.